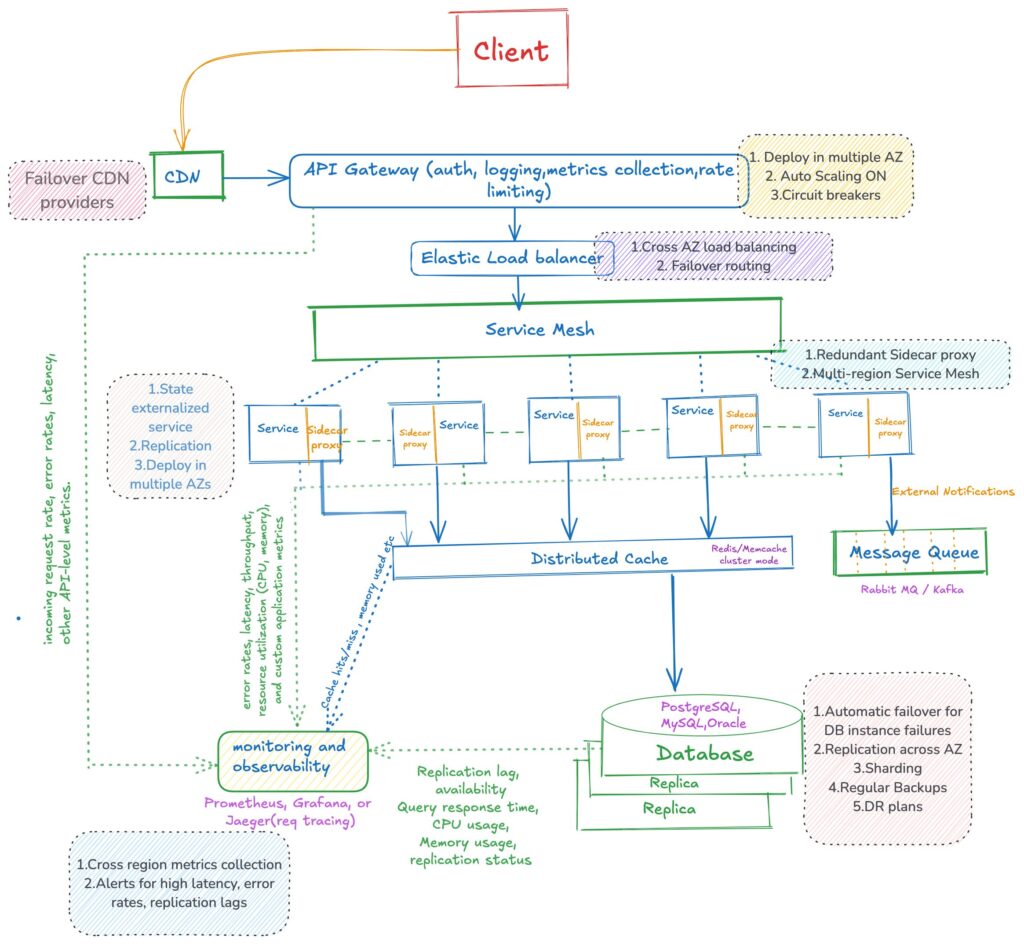
In today’s interconnected world, software systems are expected to deliver uninterrupted services despite inevitable failures. With increasing demands for availability, reliability, and scalability, designing systems that can gracefully handle failures is paramount. In this blog post, I will explore how fault tolerance can be implemented at various levels of a microservices-based system architecture.
Understanding Fault Tolerance
Fault tolerance—the ability of a system to function correctly even when parts fail—is a fundamental characteristic of resilient systems. Designing systems with fault tolerance as key characteristic enables systems to overcome unexpected systemic issues. Also achieving 100% resiliency in any system is practically impossible due to inherent limitations, including unpredictable failures, human errors, and resource constraints.
Instead of collapsing entirely, fault-tolerant systems degrade gracefully, allowing core functionalities to persist. For example, AWS S3’s 99.999999% durability (“eleven nines”) for stored data demonstrates a highly reliable system but still acknowledges that absolute perfection isn’t feasible.
Key Principles of Fault Tolerance
There are four key principles for achieving fault tolerance in any layer of a software system, whether it is at the hardware, database, or application level.

Data Replication – Ensuring Data Availability
Data replication is a strategy that falls under the concept of Redundancy. Replication ensures multiple copies of data is stored in Availability Zones (AZs) or geographic locations. This approach protects against the data loss and improves read performance by serving the requests from least-loaded or nearest replica.
Synchronous Replication vs Asynchronous Replication
| Synchronous Replication | Asynchronous Replication |
| Ensures strong consistency by applying updates to all replicas before confirming the write operation. | Writes are acknowledged immediately, and replicas are updated later. |
| Eg : In financial systems, synchronous replication ensures that account balances are always consistent. | Eg: A content management system with a primary database in one region and eventual consistency in others. |
Database-Level Fault Tolerance
Databases are critical to software systems, and their failure can bring down the entire application. Fault tolerance in databases ensures data consistency, durability, and availability.
Techniques to achieve database fault tolerance:
Replication
Replication involves creating and maintaining multiple copies of data across different nodes or locations. It ensures that the database remains available even if one node fails.
Replication protects against data loss caused by hardware or software failures. It enhances read performance by load-balancing read queries across replicas and supports disaster recovery by distributing replicas across geographically diverse locations.

Sharding
Sharding divides the database into smaller, more manageable pieces (shards), each stored on a separate server. This prevents overloading any single node and enhances scalability. Sharding can be applied at table level or database level.
Table level sharding
Individual tables are divided into smaller partitions (shards) based on a shard key, such as a user ID or timestamp. Each shard contains a subset of the table’s data and is stored on a separate server.
Suitable for applications with a few large tables where partitioning these specific tables is sufficient.Reduces query latency by limiting queries to specific shards rather than scanning an entire table.
Database level sharding
Entire databases are divided into smaller, independent databases, each stored on a separate server. Each shard contains a complete set of tables but for a subset of the data (e.g., a specific customer segment).
Suitable for systems with many tables and a need to isolate data at a higher level, such as per tenant or per region.

Application-Level Fault Tolerance
Achieving application-level fault tolerance involves designing systems that can handle and recover from failures while maintaining an acceptable level of service.
The key principles of fault tolerance that enhance application resiliency include graceful degradation, failover mechanisms such as circuit breakers, and the instrumentation of recovery processes like retries with backoff.
Graceful Degradation
Graceful degradation ensures that an application continues to operate with limited functionality instead of a complete outage during failures.
Right from the start of the application design and development , effort should be made to identify critical vs non critical features. Use feature flags to dynamically enable or disable specific features without redeploying the application. For the non-critical features, as a fallback mechanism, provide default responses or cached data.
Example : For an e-commerce application, the critical features could be checkout and search. Likewise non-critical features could be recommendation engine and analytics. In the event of stress on the system, as part of graceful degradation, for non-critical feature like recommendation, we could just show the popular product recommendations instead of running personalization.
Circuit Breakers
A circuit breaker prevents repeated calls to a failing service, allowing it time to recover and protecting the system from cascading failures
Service Meshes and API Gateways often have built-in support for circuit breakers as part of their fault tolerance and resiliency features. Eg: AWS API gateway, NGNIX, Linkerd, Consul Connect
The service mesh monitors requests and responses between services. Circuit breakers are configured with thresholds for errors, timeouts, or latency spikes. and a Fallback Behavior (circuit breaker trips) triggers in when thresholds are exceeded, and requests are stopped or rerouted.
Retry with Backoff
Retrying failed operations with increasing delays reduces the load on recovering systems and increases the chances of success.
There are different strategies for retries, namely exponential backoffs, Jitters , setting retry policies.
- Exponential backoffs – Use progressively longer wait times between retries (e.g., 1s, 2s, 4s, 8s).
- Jitter – Add randomness to backoff intervals to avoid synchronized retries that can overwhelm the system.
- Retry Policies – Limit the maximum number of retries and define failure handling after retries are exhausted.
Most of these features are often available at various levels of software and tools. In application code, they can be effortlessly added before database calls or while awaiting responses from other services.
Fault Tolerance in Caching Systems
Caching systems are considered faulty when they deliver stale data, become unavailable, or introduce data inconsistencies. Fault tolerance in caching ensures that these issues are handled gracefully to maintain system reliability.
Cache Replication
Cache replication creates multiple copies of the same cached data across nodes or regions to ensure availability and fault tolerance. Caches are replicated to multiple servers or regions to prevent downtime caused by the failure of a single node. In a cluster setup, if one cache node fails, other replicas continue to serve requests. Having cache replication feature in place helps to navigate node failures at application level.
There are other techniques as well, such as setting automatic cache eviction policies( LRU1, LFU, TTL) and handling cache misses, which are typically configured by default in most caching databases
Note: I’ve always had this question in my mind until now: If Redis is a distributed cache, where does cache replication fit in? Here’s the clarification, in case this is one of your questions as well.
Cache replication involves creating multiple copies of the same cached data across nodes or regions to ensure availability and fault tolerance.
In Redis, this is achieved through master-replica replication, where the primary node handles writes and replicas synchronize data from it. If the primary node fails, a replica can take over as the new primary, improving availability and supporting disaster recovery.
Distributed caching, on the other hand, splits the data across multiple nodes, with each node storing a portion of the data.
In Redis, this is done using Redis Cluster, where data is distributed based on hash slots, allowing horizontal scaling. Fault tolerance is maintained by assigning replica nodes to each shard, so if a node fails, its replica takes over.
Wrapping up!
While no system can be entirely fault-proof, the goal is to design with enough redundancy and flexibility to minimize disruptions and ensure continuity of service. By implementing some or all of the fault tolerance strategies discussed above, we can build a robust system that is both scalable and resilient, capable of handling unexpected challenges while maintaining a seamless user experience.
That being said, there are other important areas I haven’t covered yet, such as Chaos Engineering, the Bulkhead Pattern in microservices architectures, and Distributed Consensus in big data systems. I plan to explore these topics in more detail in upcoming blog posts, so stay tuned!
- LRU – Least Recently Used,
LFU – Least Frequently Used,
TTL – Time To Live ↩︎