The Growing Need for Federated Query Engines
Have you ever encountered a use case where you need to gather data from multiple databases to arrive at a solution? For instance, analyzing sales across different categories or calculating revenue flowing through multiple channels —such cases often involve data may be residing in different data storage solutions.
Most of the organizations adapt to different setups of data flow that is inevitability becomes spread across different storage solutions, such as on-premise databases, cloud services, and data lakes. A traditional centralized database often fails to handle such diverse environments without having to pull data into a data warehouse and this creates the need for federated query engines—tools that allows to query data from multiple sources as if they were a single, unified system.
What is Federated Query Engine?
A federated query engine enables querying data from multiple sources—such as databases, data lakes, or cloud storage—without requiring data movement or duplication into a centralized data warehouse. This allows seamless access to distributed data as if it were part of a single database, providing flexibility, scalability, and cost efficiency in data management.
Federated query engines aren’t exactly new, but they’re still a bit under the radar for many. Working in a data team, cannot emphasize enough on how important it is to get quick turn around in the event of data consolidation need or data integrity issues. And there are many organizations that already use federated query engines to seamlessly query data across multiple storage solutions. Some well-known examples include:
- Amazon Athena with AWS Glue Data Catalog
- Presto/Trino – Open-source distributed SQL engines, for querying data from multiple sources.
- Google BigQuery Omni – Enables cross-cloud querying across AWS, Azure, and Google Cloud. (This is interesting!)
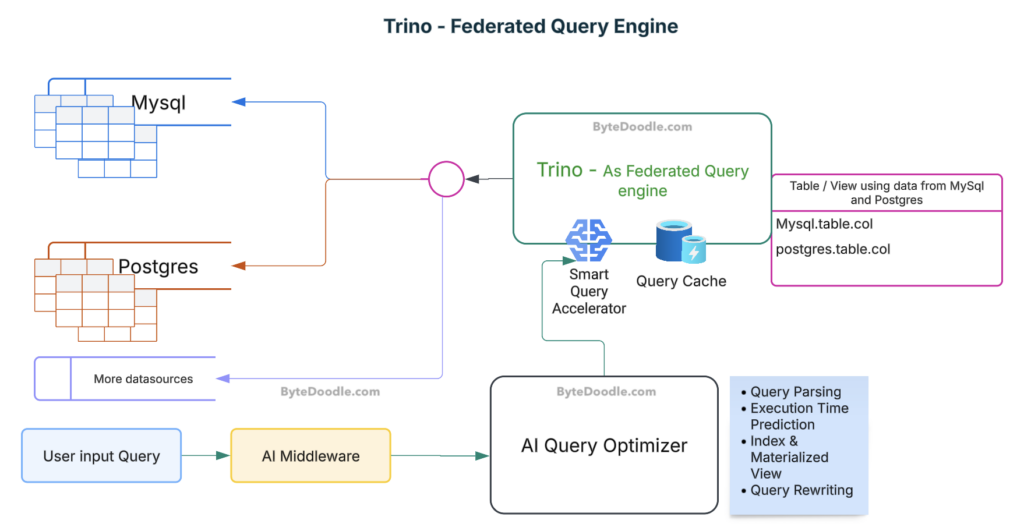
Trino as Federated Query Engine (Open-source)
Trino (formerly PrestoSQL) is a distributed SQL query engine designed for fast analytics on large datasets. It excels as federated query engine by enabling query executions using data from multiple disparate data sources including MySQL, PostgreSQL, MongoDB, Hadoop, and S3, using a single SQL interface.
Trino requires specific configurations to enable federated querying and smart query acceleration. By default, Trino is designed for distributed SQL querying, but to optimize performance and enable smart query acceleration, additional setup is needed. It’s pluggable architecture supports multiple connectors to interact with external databases. Each connector allows Trino to read and write data as if it were a native SQL database.
Along with many other amazing features that Trino supports, for the purpose of this blog post, the focus is on setting up federation part in Trino.
Check out the projects on my Github – Federated-Query-Engine
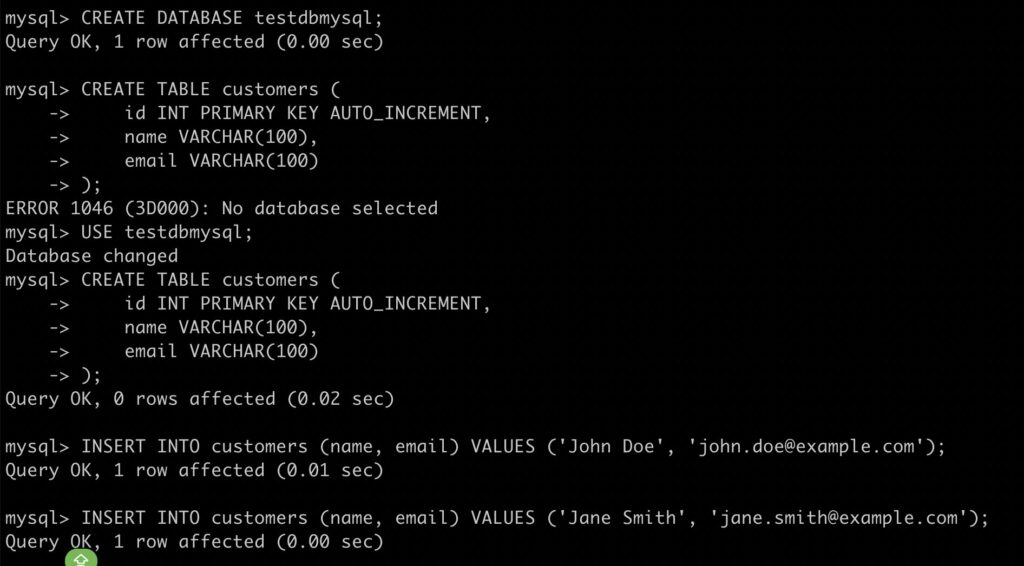
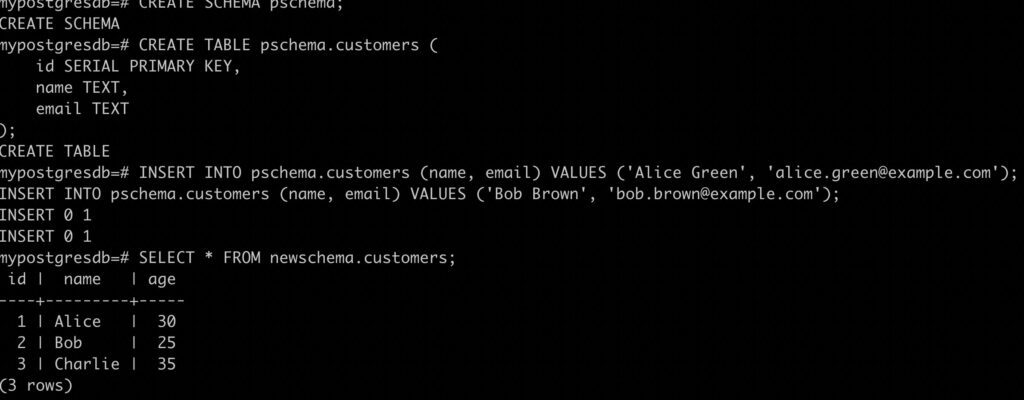
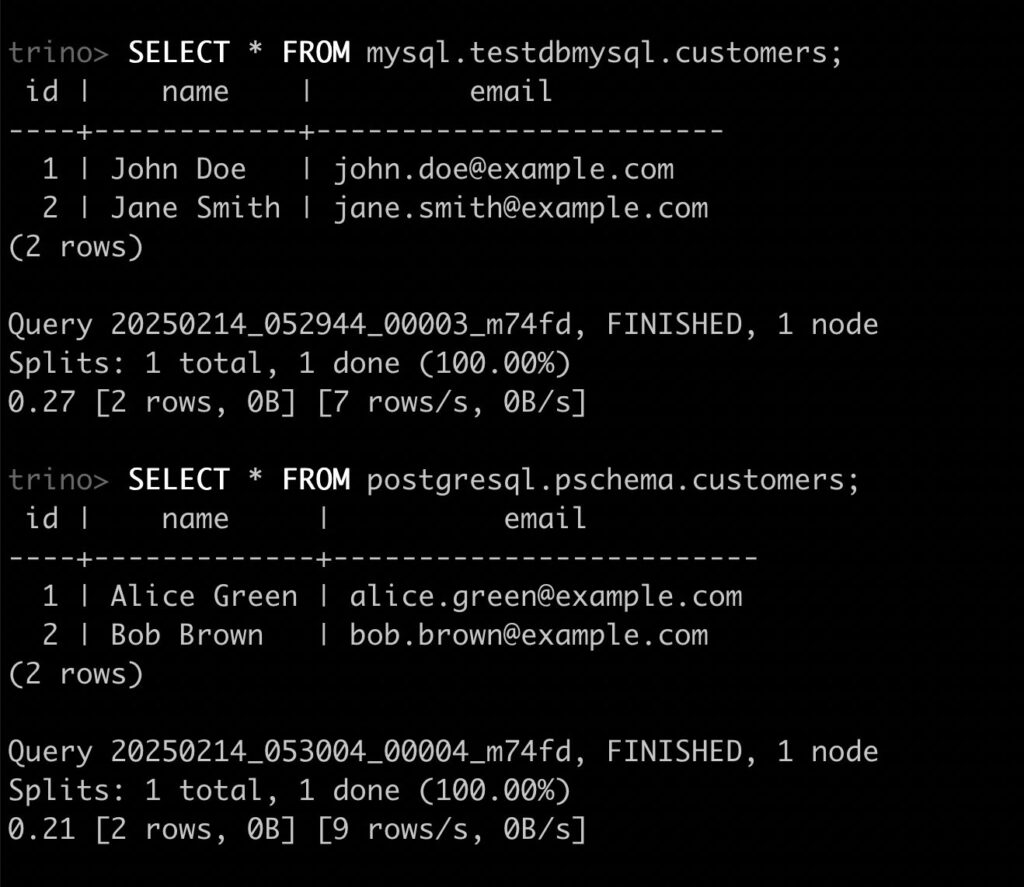
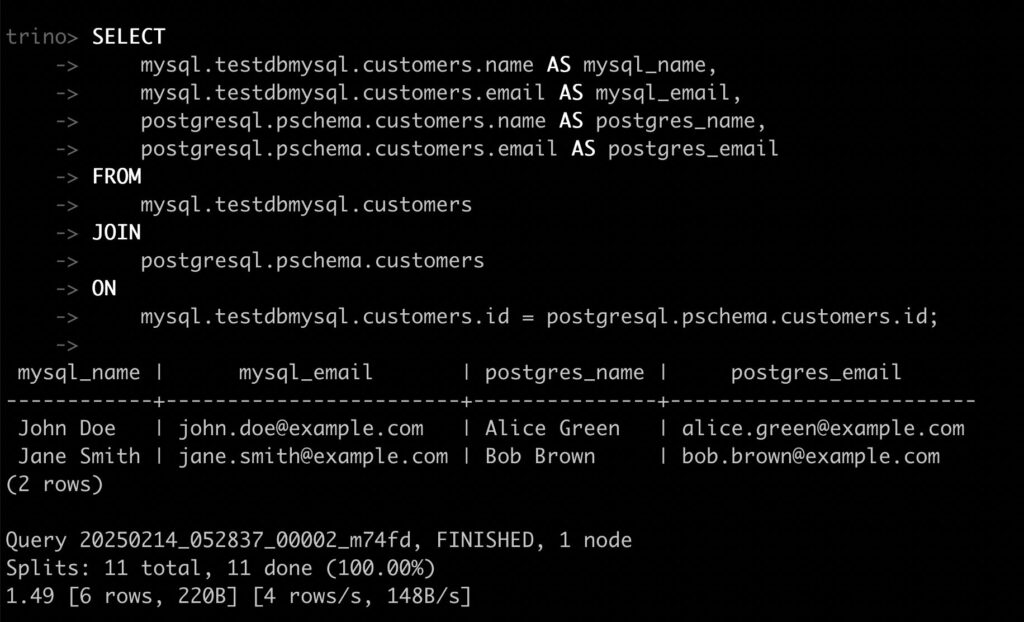
Federated Join Query on data from mysql.testdbmysql.customers and postgresql.pschema.customers
There are several benefits that use of federated query bring into data processing eco systems. Most notable are
Unified Access to Distributed Data
Ability to query multiple databases and data lakes without manual data consolidation.
Real-Time Data Insights:
Enables real-time querying across systems without waiting for batch data processing.
Cost-Efficiency: Eliminates the need for costly ETL pipelines by directly querying source systems.
Before exploring on, how AI can enhance federated query engines, it’s important to understand the challenges they face. Federated query engines are super useful, but they do come with a few challenges. Here are some of the common ones:
Performance Issues
Since federated query engines are querying multiple data sources, performance can suffer, especially if the data is spread across different systems with varying speeds. Optimizing query performance is a constant challenge.
Data Inconsistencies
Different systems may have different data formats, schemas, or even time zones, leading to inconsistencies when aggregating or joining data.
Data Latency
Federated queries involve live connections to remote data sources, which can introduce latency. The performance of a federated query depends largely on the network connection and the performance of the external systems and various other factors like indexing etc.
Complexity in Query Optimization
Complex queries with varying data volumes and patterns bring added challenges in distributed query execution across multiple systems.
Smart Query Acceleration
It refers to a technique used to optimize query execution in a federated query engine by reducing query latency, minimizing data movement and improving performance. It involves intelligent query planning, caching, indexing, and AI-driven optimizations to ensure faster and more efficient query execution across multiple data sources.
There are few things that can be done to achieve this:
- Configure connectors to support pushdown features (e.g.,
predicate_pushdown_enabled=true) .This can be setup in the catalog configuration for a given DB or datasource. - Set
dynamic_filtering.enabled=truein Trino’s configuration, this reduce data scans. - Configure
query.max-memoryandquery.max-spill-per-nodefor optimal resource utilization. - Adjust
task.concurrencyandtask.max-worker-threadsfor parallel execution.
Trino doesn’t have built-in caching, but an external caching solutions like Alluxio, Memcached or Redis could solve for the caching feature. If the goal is to cache query results inside Trino itself, Materialized Views are a great option. Trino supports materialized views with databases like Hive, Iceberg, and Delta Lake.
CREATE MATERIALIZED VIEW cached_view AS
SELECT column1, column2
FROM test_table
WHERE column3 > 100;
REFRESH MATERIALIZED VIEW cached_view;
SELECT * FROM cached_view;
AI-Driven Optimization for Federated Queries
To enhance query performance, AI can be integrated into query pipelines to create automatic indexes, auto rewrite of queries that are inefficient, dynamically.
Real-Time Query Tracking and Enhancements
Trino has a metadata table that records several key metrics for queries that are executing. The table becomes an anchor in real time query tracking and predictions.
So, basically the steps are:
- Read Trino logs in realtime
- Figure out slow running queries
- Run a model to continuously train on the logs, this helps to learn the pattern eventually.
- Intercept the queries from Trino query pipeline
- Modify query or create index based on the requirements.
- Run the queries!

system.runtime.queries schema
To sum it up, with Trino’s real-time query optimization, we’re looking at a new level of performance. By combining the power of federated systems with intelligent query acceleration, we can boost speed, get insights faster, and make data processing much more efficient.
It’s been a lot of learning, but I’ve really enjoyed it! Excited to keep exploring and sharing more!
References:
https://trino.io/docs/current/connector.html
https://thenewstack.io/speed-trino-queries-with-these-performance-tuning-tips